
what is data preprocessing in Hindi
data preprocessing in data miningdata preprocessing एक data mining technique है जिसका यूज raw data को महत्वपूर्ण और effective format में change करने के लिए किया जाता है.
Real world में जो data होता है वह generally incomplete , noisy, एवं inconsistent होता है.
incomplete का means है कि उसमें attributes की कमी होती है.
noisy का means है कि इसमें errors होती है.
inconsistent का means है कि डेटा में विसंगतियाँ और डेटा duplicate होता है.

data preprocessing steps in Hindi
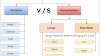
data preprocessing में निम्नलिखित three steps होते हैं :
- Data cleaning
- Data transformation
- Data Reduction
Data cleaning in data mining
डेटा जो है वह irrelevant (अप्रासंगिक) हो सकता है एवं इसके कुछ भाग missing हो सकते है. इसलिए data cleaning की जरूरत पड़ती है.
Data cleaning में missing data, noisy data etc. को handle किया जाता हैें .
a.) Missing data :यह situation तब generate होती है जब data में से कुछ data missing होता है.
इसको हम निम्नलिखित प्रकार handle कर सकते है :
- tuples को ignore करना : यह approach तभी useful होती है जब हमारे पास बहुत बड़ी quantity में dataset होता है. एवं एक tuple के अंदर बहुत सारी values missing रहती है.
- missing values को fill करना : missing values को fill करने के Multiple methods होते है.
noisy data जो है वह unused (useless data) होता है और इसे मशीन के द्वारा interpret नहीं किया जा सकता.
faulty data को collect करने से एवं data entry में errors आने इत्यादि से noisy data generate हो जाता है.
Noisy data को निम्नलिखित तरीकों से handle किया जा सकता है :
binning method in data mining
:इस technique का यूज sorted data पर किया जाता है.
इसमें पूरे data को equal size के segments में divide कर लिया जाता है एवं multiple methods का यूज task को complete करने के लिए किया जाता है.
Each segments को अलग अलग handle किया जाता है.
Regression
:इस technique में regression function का यूज किया जाता है.
regression दो प्रकार का होता है.
- linear regression
- multiple regression.
linear regression में एक variable का यूज किया जाता है जबकि multiple regression में दो से ज्यादा variables का यूज किया जाता है.
Clustering in data mining
इसके द्वारा same type के data को एक cluster में रखा जाता है एवं जो noisy data होता है वह cluster के बाहर हो जाता है.
Data transformation in data mining
यह data preprocessing का second step है.
Data transformation के द्वारा, data को data mining की process के लिए यूजफुल form में change किया जाता है.
Data transformation के निम्नलिखित तरीके होते हैं :
- Normalization : data values को एक special range में मापने के लिए इसका यूज किया जाता है. यह range है (-1.0 से 1.0 या 0.0 से 1.0).
- attribute section:– attribute section method में, नए attributes को दिए गये attributes के set से Implement किया जाता है.
- Discretization: Discretization का यूज numerical attributes की raw values को replace करने के लिए किया जाता है.
- Hierarchy generation : Hierarchy generation में low-level के attributes को high level attributes में change कर दिया जाता है. जैसे:- attribute “state” को attribute “country” में change कर दिया जाता है.
Data reduction in data mining
यह data preprocessing का third step है.
data mining एक ऐसी प्रक्रिया है जिसका use very large quantity के data को handle करने के लिए किया जाता है.
Large quantity के data के साथ काम करने के कारण कभी कभी analysis करना बहुत ही complex हो जाता है. इस problem को दूर करने के लिए हम data reduction technique का उपयोग करते है.
इस technique का main goal storage capability को increase और analysis costs को decrease करना होता है.
data reduction steps
data reduction के steps निम्नलिखित है :
- Data Cube Aggregation in data mining : data cube को implement करने के लिए aggregation operation को data पर apply किया जाता है.
- Attribute Subset Selection : इसमें उचित attributes का use किया जाता है. एवं बाकी के attributes को discard कर दिया जाता है.
- Numericity Reduction : इसके द्वारा पूरे data को store करने की बजाय हम only data के model को store करते है.
- Dimensionality Reduction :यह encoding methods के through data के size को decrease कर देता है. यह lossy या lossless दोनों में से कोई भी हो सकता है.
methods of Dimensionality Reduction
Dimensionality Reduction के 2 effective methods है :
- wavelet transforms
- PCA (principal component analysis).




0 Comments